De Microservicios a una Solución Austera: Construyendo un CMS Self-Hosted por menos de 10 dólares
El contenido de este blog ha sido generado por un humano; se ha utilizado generación artificial únicamente para ayudas de redacción y ortografía.
Una de las cosas que acordamos con Nicolás, mi compañero de tesis, cuando buscábamos un tema para nuestro trabajo de titulación, fue que, independientemente de la elección, lo único importante era que fuese aplicable en la industria. Queríamos un pretexto para aprender alguna buzzword que, quizás, pudiera añadir valor a nuestros CVs. Así, elegimos un problema que giraba en torno a una arquitectura específica: los microservicios. El resultado fue similar a la siguiente imagen.
A medida que ganaba experiencia en la industria, comencé a darme cuenta que a mis colegas que les toca la responsabilidad de tomar decisiones de diseño les ocurría el mismo error que en mi tesis:
- orquestación en aplicaciones que fácilmente podrían correr en pequeños servidores;
- frontends diseñados como micrositios, cuando hasta el motor de plantillas de Django haría el trabajo de forma más eficiente;
- dinero perdido en soluciones de load balancing para proyectos de baja escala, etc.
¿Y si intentaba hacer las cosas de forma diferente? ¿Y si utilizaba la austeridad como idea principal para un proyecto personal? La idea me pareció lo suficientemente motivante.
Probando algo distinto
Ya tenía la idea, ahora necesita un medio. Buscaba en problema simple y genérico, y la verdad es que no tuve que hacer mucho esfuerzo para definirlo: un sitio con contenido estático y dinámico, que permita a una persona con conocimientos básicos de informática gestionar contenido mediante un dashboard, para luego, consumir el contenido mediante un frontend moderno. Inmediatamente pensé en lo obvio: ¿Por qué no usar Wordpress? Y me acordé de mi mala experiencia como desarrollador:
- siempre que he intentado salirme del caso de uso típico termino enojado
- no me gusta el enfoque híbrido que tiene (personas corrientes y desarrolladores), porque al final los desarrolladores son los que terminan pagando las inconsistencias
- el stack está desactualizado
No me tomen mal, Wordpress hace muy bien su trabajo cuando es justificada su elección, pero en este caso (como yo soy el dueño del producto), la experiencia de desarrollo es fundamental, por lo que, si iba a elegir un gestor de contenidos debía ser Developer first.
En pocas palabras, lo que necesitaba era un headless CMS, que es básicamente un gestor de contenidos común y corriente, pero que presenta únicamente la parte del backend 1.
Esta no sería mi primera experiencia utilizando este tipo de herramienta. Hace unos pocos años, se me presentó la necesidad de editar mi sitio en Hugo desde un móvil, y el flujo basado en Git que me ofrecía Netlify (mi proveedor en ese momento) era, por decirlo de alguna forma, tedioso. Buscando opciones, me encontré con los Headless CMS, y en específico con Decap CMS (antes Netlify CMS). Se ajustaba perfectamente a mis necesidades.
Hasta el día de hoy sigo ocupando Decap CMS, de hecho, lo recomiendo si es que se quiere un panel de administración en un blog, pero para un problema mas complejo que ese dominio se queda chico, por lo que tuve que buscar alternativas, y sí…, hay muchas, tantas que hay un sitio dedicado a compararlas; por lo que intenté tener el enfoque que me ha dado resultado últimamente (no…, no es preguntarle a un LLM): probar arbitrariamente una y cuando encuentre algo que no me gusta intentar otra. La primera que probé fue Keystone.js (spoiler: no probé otra, porque cuando me di cuenta de desventajas ya era demasiado tarde).
Backend (Keystone)
Considerando que me siento más cómodo utilizando el ecosistema de Javascript, elegir Keystone fue una decisión lógica:
- Developer First: Osea… tiene el slogan “The superpowered CMS for developers”;
- Utiliza Typescript como lenguaje;
- Expone una API de GraphQL usando un server de Apollo;
- Define el modelo de datos utilizando Prisma ORM;
- Genera un panel de administración en Nextjs.
Así luce la estructura de un proyecto genérico en Keystone:
.
├── auth.ts # Authentication configuration for Keystone
├── keystone.ts # The main entry file for configuring Keystone
├── node_modules # Your dependencies
├── package.json # Your package.json with four scripts prepared for you
├── package-lock.json # Your npm lock file
├── README.md # Additional info to help you get started
├── schema.graphql # GraphQL schema (automatically generated by Keystone)
├── schema.prisma # Prisma configuration (automatically generated by Keystone)
├── schema.ts # Where you design your data schema
└── tsconfig.json # Your typescript config
Keystone hace más fácil las tareas de desarrollo, por ejemplo provee una interfaz de comandos interesante.
npm run dev ejecuta la framework en modo desarrollador y genera los siguiente archivos que son esenciales:
schema.graphql: definiciones de la API de GraphQLschema.prisma: definiciones de Prisma ORM.keystone/: directorio donde se puede encontrar el panel de administración de Nextjs
Luego, refleja las definiciones de schema.prisma en la base de datos; levanta el servidor de Apollo (que puede ser consultado utilizando las queries definidas en schema.graphql); y levanta el panel de administración2 .
 Es importante mencionar que
Es importante mencionar que schema.graphqly schema.prisma deben ser agregados al control de versiones, y también las migraciones de la base de datos (npn run generate), con el fin de que sea más fluido el despliegue en producción.
Los bloques de construcción del modelo de datos se agrupan en un objeto llamado list; por ejemplo una tabla ficticia de usuarios luce similar a:
const User = list({
access: {
operation: {
query: allowAll,
create: isAdmin,
update: isAdmin,
delete: isAdmin,
},
},
fields: {
name: text(),
email: text({ isIndexed: 'unique' }),
password: password(),
isAdmin: checkbox(),
},
});
Notar que las columnas de la tabla de usuario se definen utilizando el atributo fields, en el ejemplo anterior se definen 4 columnas: name, email, password, isAdmin; con los tipos text(), text(), password(), checkbox() respectivamente (para mayor información visitar la documentación oficial de la API).
También, se pueden definir permisos por cada operación CRUD sobre la list. En el ejemplo anterior, solo el rol administrador puede crear, actualizar y eliminar, mientras que un usuario corriente solo puede leer.
(Lo anterior es la introducción más simplificada que se me ocurrió hacer de Keystone, recomiendo visitar la documentación –que es bastante amigable con los principiantes–).
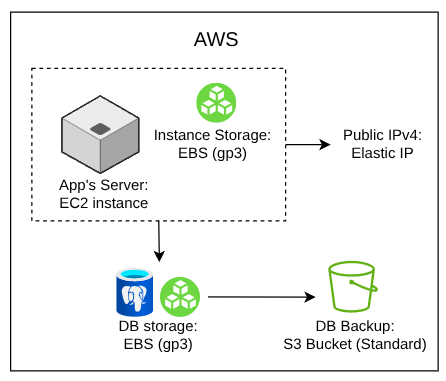
Infraestructura
En la documentación encontré ejemplos de despliegue para Heroku, Microsoft Azure y Railway; pero al no ver a la nube con la que me siento más cómodo (AWS), pensé que era un buen momento de poner mis conocimientos en práctica y crear mi propio despliegue. Solo tenía que diseñar la infraestructura.
Si es que mi intención era abaratar costos entonces tenía que alojar la base de datos en la misma máquina que la aplicación de Keystone 3. Me pareció razonable desacoplar la lógica dentro del servidor mediante alguna herramienta simple de gestión de contenedores.
También, tenía que considerar que como Keystone provee un panel de administración y una API, debía hacer asequible el tráfico hacia la CMS mediante algún tipo de proxy. Y por último, si es que pensaba llamar a este sistema “producto” debía al menos desacoplar el almacenamiento de la base de datos y proveer algún mecanismo de respaldo (idealmente hacia un object storage).
La siguiente imagen describe el diseño de la infraestructura:
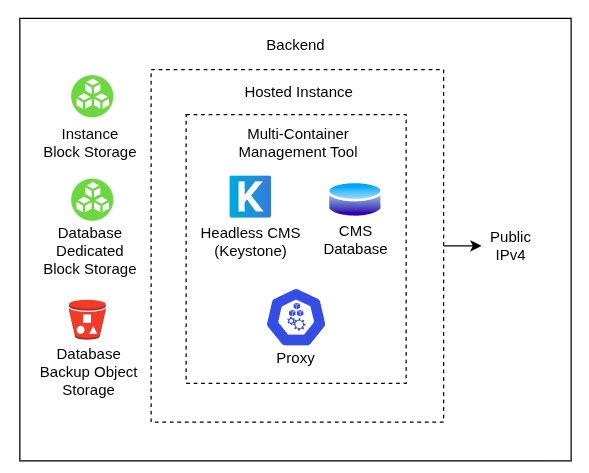
Base de datos
Postgres, en mi opinión, mantiene un buen equilibrio entre minimalismo y características, por lo que mi problema en esta área se resumió a buscar una herramienta para generar backups y Point-in-Time Recovery con la menor fricción posible. Así, llegué a pgbackrest, que incluso contaba con un paquete en la última versión estable de Debian. Me decidí inmediatamente.
Por otra parte, pgbackrest facilita la tarea de guardar los backups en una solución de almacenamiento externa. En mi caso, utilicé S3 (el proceso se encontraba bien documentado).
Orquestación
Los contenedores que se deben considerar son los siguientes:
- aplicación CMS
- base de datos + backups 4
- proxy, hacia los dos contenedores anteriores
Esta vez, no iba a cometer el mismo error que mencioné al inicio del post. Dado que la aplicación es simple, Docker Compose es más que suficiente. Solo necesitaba elegir un proxy, y para este caso elegí Traefik. Así, la configuración de docker-compose.yml quedó de la siguiente forma56:
version: "3.3"
services:
traefik:
image: "traefik:v3.3"
container_name: "traefik"
command:
#- "--log.level=DEBUG"
- "--api.insecure=true"
- "--providers.docker=true"
- "--providers.docker.exposedbydefault=false"
- "--entryPoints.web.address=:80"
ports:
- "80:80"
- "8080:8080"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro"
postgres-ks-app:
# image: postgres:15-bullseye
# volumes:
# - postgres-ks-app-data:/var/lib/postgresql/data
# env_file:
# - .env
image: pgplusbackup
volumes:
- ./db/postgresql.conf:/etc/postgresql/postgresql.conf
- ./db/pgbackrest.conf:/etc/pgbackrest.conf
- ./db/initdb:/docker-entrypoint-initdb.d
- ${DB_DATA_DIR}:/var/lib/postgresql/data
env_file:
- .env
command: ["-c", "config_file=/etc/postgresql/postgresql.conf"]
ks-app:
image: ${APP_IMG}
labels:
- "traefik.enable=true"
- "traefik.http.routers.test_app.rule=Host(`${APP_HOST}`)"
- "traefik.http.routers.test_app.entrypoints=web"
- "traefik.http.services.myservice.loadbalancer.server.port=${APP_PORT}"
restart: on-failure
env_file:
- .env
volumes:
postgres-ks-app-data:
Para mayor detalle de las variables de entorno y archivos de configuración necesarios para levantar los contenedores consultar https://github.com/CespedesCI/ktp-cm/tree/master/cluster_schema.
Observabilidad
Una de las cosas que nunca me ha acomodado de AWS es la gestión de la observabilidad. ¿Deseas métricas de algún recurso adicional y personalizado, como la memoria en una instancia? Cobro adicional. ¿Deseas dashboards personalizados? Cobro adicional. ¿Deseas métricas actualizadas con intervalo menores a cinco minutos? Cobro adicional. Y así, con un sinfín de métricas.
Fundamentalmente, me interesaba obtener métricas de recursos (memoria, CPU y red) en intervalos de tiempo cortos e, idealmente, visualizarlas en un dashboard. De esta manera, podría realizar pruebas de carga para determinar si la instancia elegida era viable.
Primero, intenté ver si era factible usar uno de los proyectos insignia de monitoreo de la CNCF: Prometheus. Pero consideré que agregaba más complejidad de la necesaria. Otra opción era Grafana Agent, pero considerando que ha sido deprecado en favor de Grafana Alloy, me hiceron optar por este último.
Grafana Alloy es un colector de telemetría que utiliza el framework de monitoreo OpenTelemetry. Es de fácil despliegue en Grafana Cloud, que, por cierto, tiene un generoso plan gratuito. Así, con unos pocos clics, es posible levantar un colector de recursos en un servidor Linux.
Integración Continua
A grandes rasgos espero que el repositorio del backend integre un worker que haga:
- suite de tests
- publicación hacia un registro de contenedores
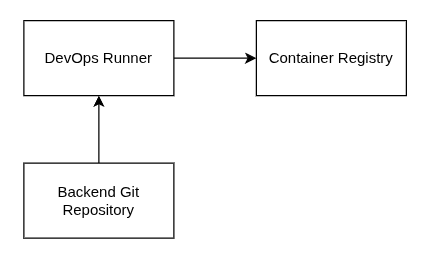
Github provee toda la infraestructura que se necesita: repositorio, runners y un registro de contenedores.
A continuación, se describe la implementación de la integración utilizando github actions (primero: pruebas de integracion con Jest; segundo: publicación hacia registro).
name: Pull request based pipeline
on: pull_request
jobs:
# Label of the runner job
runner-job:
# You must use a Linux environment when using service containers or container jobs
runs-on: ubuntu-latest
# Service containers to run with `runner-job`
services:
# Label used to access the service container
postgres:
# Docker Hub image
image: postgres
# Provide the password for postgres
env:
POSTGRES_PASSWORD: postgres
# Set health checks to wait until postgres has started
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
ports:
# Maps tcp port 5432 on service container to the host
- 5432:5432
steps:
# Downloads a copy of the code in your repository before running CI tests
- name: Check out repository code
uses: actions/checkout@v4
with:
ref: ${{ github.ref }}
# Performs a clean installation of all dependencies in the `package.json` file
# For more information, see https://docs.npmjs.com/cli/ci.html
- name: Install dependencies
run: npm ci
- name: CI Test
run: npm test
env:
DATABASE_URL: postgresql://postgres:postgres@localhost:5432
Una vez que las pruebas de integración han pasado de forma satisfactoria, se realiza el merge a la rama principal, y esto desencadena una pipeline para publicar la imagen en GCR (GitHub Container Registry):
name: Publish package to GH Container Registry
on:
push:
branches: ['master']
workflow_dispatch:
# Defines two custom environment variables for the workflow. These are used for the Container registry domain, and a name for the Docker image that this workflow builds.
env:
REGISTRY: ghcr.io
IMAGE_NAME: ${{ github.repository }}
jobs:
# Label of the runner job
runner-job:
# You must use a Linux environment when using service containers or container jobs
runs-on: ubuntu-latest
# Sets the permissions granted to the `GITHUB_TOKEN` for the actions in this job.
permissions:
contents: read
packages: write
attestations: write
id-token: write
steps:
- name: Checkout repository
uses: actions/checkout@v4
# Uses the `docker/login-action` action to log in to the Container registry registry using the account and password that will publish the packages. Once published, the packages are scoped to the account defined here.
- name: Log in to the Container registry
uses: docker/login-action@65b78e6e13532edd9afa3aa52ac7964289d1a9c1
with:
registry: ${{ env.REGISTRY }}
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
# This step uses [docker/metadata-action](https://github.com/docker/metadata-action#about) to extract tags and labels that will be applied to the specified image. The `id` "meta" allows the output of this step to be referenced in a subsequent step. The `images` value provides the base name for the tags and labels.
- name: Extract metadata (tags, labels) for Docker
id: meta
uses: docker/metadata-action@9ec57ed1fcdbf14dcef7dfbe97b2010124a938b7
with:
images: ${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}
# This step uses the `docker/build-push-action` action to build the image, based on your repository's `Dockerfile`. If the build succeeds, it pushes the image to GitHub Packages.
# It uses the `context` parameter to define the build's context as the set of files located in the specified path. For more information, see [Usage](https://github.com/docker/build-push-action#usage) in the README of the `docker/build-push-action` repository.
# It uses the `tags` and `labels` parameters to tag and label the image with the output from the "meta" step.
- name: Build and push Docker image
id: push
uses: docker/build-push-action@f2a1d5e99d037542a71f64918e516c093c6f3fc4
with:
context: .
push: true
tags: ${{ steps.meta.outputs.tags }}
labels: ${{ steps.meta.outputs.labels }}
- name: Delete old versions
uses: actions/delete-package-versions@v5
with:
package-name: ${{ github.event.repository.name }}
package-type: 'container'
min-versions-to-keep: 1
delete-only-untagged-versions: 'true'
Es importante notar que, al trabajar con el tier gratuito de GCR, se debe tener cuidado de no sobrepasar el límite de almacenamiento, lo que significa que hay que ir eliminando las versiones antiguas de la aplicación (el último trabajo en la pipeline anterior).
Despliegue Continuo
El estado deseado para el despliegue es una aplicación que haya superado todas las pruebas de integración y que, además, haya publicado una nueva versión de su imagen en un registro de contenedores.
Cuando se desencadena la pipeline de despliegue, se espera que:
- En la VPS donde se ejecuta el contenedor de la aplicación, se debe hacer pull de la nueva imagen desde el registro.
- Utilizando una herramienta que permita la estrategia Zero Downtime Deployment, se levanta la nueva versión de la aplicación. Buscando herramientas, encontré docker-rollout. Así, bastó con ejecutar
docker-rollout <container-app-name>para realizar un despliegue tipo blue-green.
El flujo queda demostrado por la siguiente pipeline:
name: Deploy to EC2
# Controls when the workflow will run
on: workflow_dispatch
env:
REGISTRY: ghcr.io
IMAGE_NAME: ${{ github.repository }}
BRANCH_NAME: ${{ github.head_ref || github.ref_name }}
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- uses: actions/checkout@v4
- name: SSH Remote Commands
uses: appleboy/ssh-action@v1.2.0
with:
host: ${{ secrets.HOST }}
username: ${{ secrets.USERNAME }}
key: ${{ secrets.KEY }}
port: ${{ secrets.PORT }}
script: |
cd ${{ vars.INFRA_DIR }} && \
docker pull ${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}:${{ env.BRANCH_NAME }} && \
docker rollout ${{ vars.COMPOSE_SERVICE_NAME }} --wait-after-healthy ${{ vars.HEALTHY_TIME }} && \
yes | docker image prune
Es necesario proveer, mediante la configuración de la infraestructura, ciertas variables como el directorio donde se encuentran los archivos de configuración del clúster.
Frontend
Posts como “You don’t need Next.js” en la front page de Hacker News a comienzos de año sembraron en mí la curiosidad por probar alternativas a Nextjs. Además, recordando la fusión de Remix y React Router en mayo del año pasado, y considerando que Remix, pese a ser eclipsado por Next.js, llevaba ya un tiempo integrándose en React Router —esta última con millones de descargas semanales—, me hicieron inclinarme por React Router en compañía de la build tool que me acomodaba más (Vite).
Con el respecto al despliegue, quería algo simple: flujo orientado a git.
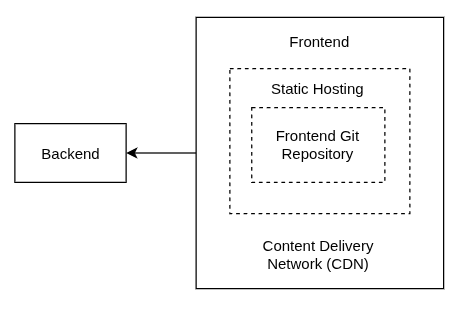
A continuación, describo los ajustes que realicé para poder hacer solicitudes básicas hacia Keystone:
Decidí ocupar Apollo Client para realizar las solicitudes. Pero no dejaba de aparecerme un error molesto con la importación de la librería. (La solución sugerida en la discusión fue suficiente).
Otra consideración es que, si se quiere aprovechar Apollo Client en su máximo potencial, se deben iniciar las queries fuera de react.
Más detalles de la implementación (plantilla) en https://github.com/CespedesCI/ktp-front.
Proveedores y Servicios
Hace ya un tiempo tenía interés de ocupar un paradigma declarativo para definir la infraestructura de un sistema. En especial había escuchado hablar a mis colegas de Terraform. Encontré que esta era la ocasión perfecta para crear una implementación en esta herramienta. El primer pasó fue definir formalmente los proveedores y servicios involucrados en la aplicación.
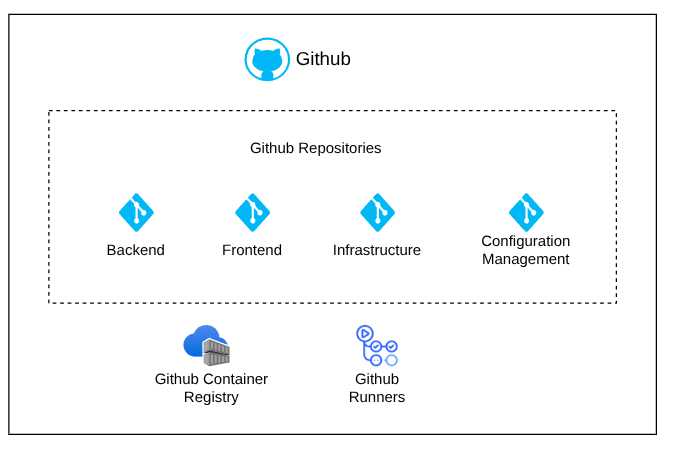
Github
| Servicio | Función |
|---|---|
| Repositorios Github | Control de versión para el backend, frontend, IaC, y gestión de configuración. |
| Github Container Registry | Registro para guardar las imágenes de las últimas versiones de la aplicación |
| GitHub-Hosted Runners | - Pipelines de integración y despliegue.- Gestión de estado de aplicación |
Grafana
| Servicio | Función |
|---|---|
| Grafana Cloud | Dashboard de analítica |
| Grafana Alloy | Observabilidad de la aplicación |
AWS
| Servicio | Función |
|---|---|
| EC2 | Instancia del backend y la base de datos |
| EBS | - Almacenamiento general de la instancia del backend.- Almacenamiento de la base de datos |
| S3 | Almacenamiento del respaldo de la base de datos |
| Elastic IP (EIP) | Exponer IPv4 pública hacia el backend |
Cloudflare
| Servicio | Función |
|---|---|
| Cloudflare CDN | Servir el frontend con rapidez |
| Static Hosting | Instancia del frontend |
| Cloudflare DNS | DNS del sistema |
HashiCorp
| Servicio | Función |
|---|---|
| Terraform Cloud | Gestión de infraestructura (estado, aprovisionamiento, recursos) |
| Vault Secrets | Gestión de secretos |
Gestión de Configuración
En la sección de despliegue continuo se asume que la instancia en la que se está ejecutando la aplicación tiene un estado deseado, por ejemplo: docker instalado, docker-rollout disponible, directorio con los archivos de infraestructura. Es decir, se necesita gestionar el estado deseado de la aplicación.
Entonces, me dediqué a buscar una herramienta de gestión de configuración ajustada a a la aplicación. En palabras simple solo quería una herramienta que me permitiera hacer SSH hacia la instancia y ejecutar un conjunto de instrucciones idempotentes para alcanzar el estado deseado. Descarté inmediatamente Cheff y Puppet porque no quería depender de otro servidor (master server). Por otra parte, Ansible tenía todo lo que necesitaba: flujo mediante SSH, idempotente, fácil configuración (archivos yaml).
¿Pero cómo llevar los datos, asociados a los recursos, necesarios para gestionar el estado (por ejemplo: bucket s3, IP del EC2, llave SSH, etc) hacia un playbook de Ansible? Un pequeño script en Python sería suficiente.
Una descripción high-level del flujo sería el siguiente:
- Obtener los recursos, necesarios, utilizando la API de Terraform.
- Generar archivos necesarios en la instancia (
docker-compose.yaml, variables de entorno para los contenedores, variables para el playbook, etc), utilizando un motor de plantillas (Jinja). - Ejecutar playbook utilizando los archivos generados.
Los detalles de implementación pueden ser consultados en https://github.com/CespedesCI/ktp-cm.
Costos
| Servicio | Costo |
|---|---|
| EC2 | t2.micro, $0.0116/hora ($0.2784/día; $8.352/mes) |
| EBS | EBS SSD (gpt3): $0.08/GB-mes. |
| S3 | S3 Standard: $0.023/GB. |
| Elastic IP (EIP) | La primera IP asociada a una instancia es gratis. |
| GitHub-Hosted Runners | Plan gratuito |
| Grafana Cloud | Plan gratuito |
| Cloudflare CDN y DNS | Plan gratuito |
| Static Hosting | Plan gratuito |
| Terraform Cloud | Plan gratuito |
| Vault Secrets | Plan gratuito (descontinuado) |
Conclusión
Mentiría si afirmase que, al finalizar el proyecto me encuentro totalmente conforme. Hay muchos detalles que me gustaría mejorar, o, en algunos casos, sustituir completamente algún enfoque:
- Considero que KeytoneCMS para proyectos pequeños agrega demasiada sobrecarga de herramientas: Prisma, Apolo, Nestjs.
- Quizás Ansible agrega mucha carga técnica para configurar los estados y es mejor ocupar una solución orientada a hacia la imagen de la instancia (como Packer).
Por el lado de los costos, podría decir que se cumplió el objetivo principal de ocupar la austeridad como idea central. El costo computacional de correr la aplicación es menor a diez dolares mensuales (sin considerar el costo variable de almacenamiento).
Por último, me habría gustado dar mayor justificación al punto anterior mediante pruebas de carga; que, de hecho, realicé mediante K6, pero, lamentablemente, perdí los resultados por la política de retención de 14 días; por lo que queda pendiente si es que vuelvo a re-visitar este proyecto.
Wordpress también puede ser configurado en modo headless CMS. ↩︎
Se puede ser más granular con que tareas ejecutar utilizando parámetros. ↩︎
En ese momento, el hosting de PostgreSQL más barato que encontré fue PGCluster a $4.19/mes (con backup y filesystem snapshot) ↩︎
Se me presentaron problemas (fundamentalmente de permisos) al intentar desacoplar pgbackrest en su propio contenedor y enlazarlo al de la base de datos. Por lo tanto, tuve que buscar una imagen con Postgres y pgbackrest en el mismo contenedor. Dado que no tuve éxito en mi búsqueda, creé mi propia imagen. ↩︎
El siguiente archivo es para modo desarrollador (en el repositorio https://github.com/CespedesCI/ktp-cm/tree/master/cluster_schema se encuentra el archivo para producción
docker-compose-prod.yaml). ↩︎El archivo asume que se esta ocupando la imagen customizada de PostgreSQL + pgbackrest llamada
pgplusbackup. En caso de querer ocupar PostgreSQL sin backups comente la imagenpgplusbackupy des-comente la imagenpostgres(en el archivo siguiente). ↩︎